
RDBのインデックス。データベースチューニングの際には耳にする言葉だけど、良く分からない。そんな人に、私と一緒にインデックスを実感しましょう。
1回目は実際にインデックスを作成してその効果を実感しましょう。
※ここでは、SQLServerを用いて作業を行っていきます。
インデックスとは
インデックスとは英語表記で”Index”、これを日本語訳すると”索引”となります。”索引”を家にあった国語辞典で調べると、
「ある書物の中の語句や事項などを、容易に探し出せるように抽出して一定の順序に配列し、その所在を示した表。インデックス。」
と書いてあります。一般的なイメージではこんな感じでしょう。
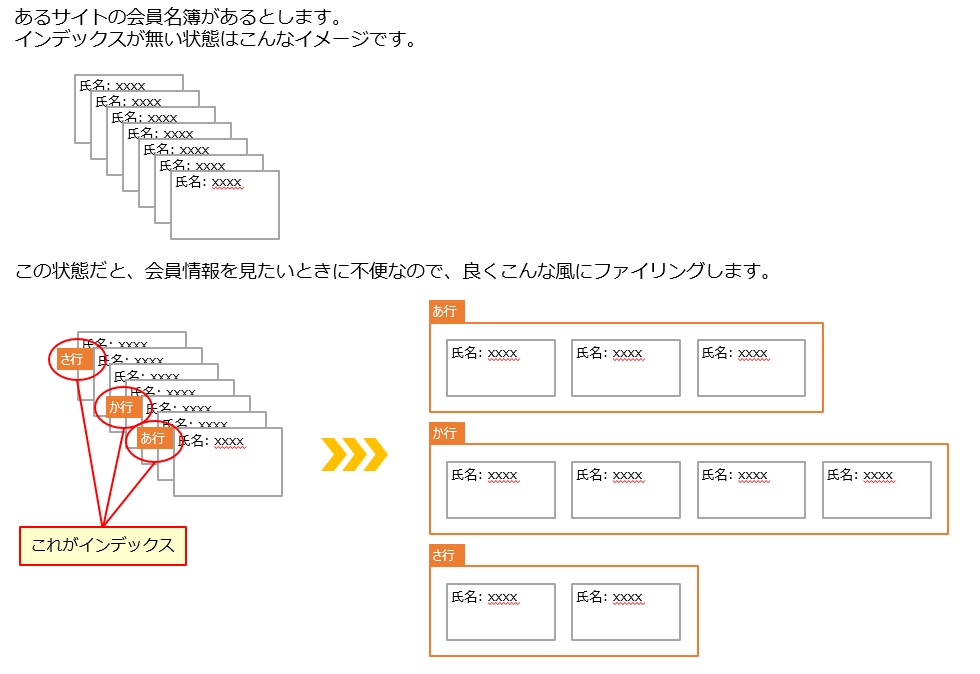
まぁ、それは分かったけど、データベースの世界では何なの?というと、
「テーブルの中の列に対して、列の値を持つ行の場所情報を保持したもの」
となります。こんなイメージです。
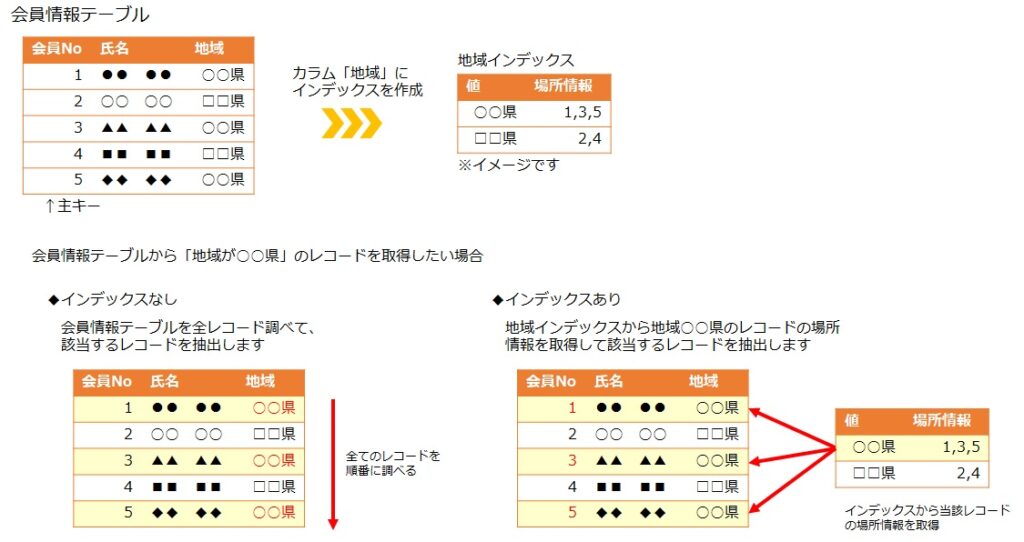
このようにインデックスはテーブルからデータを検索する際に効果を発揮するもので、検索する母体のデータ量が多ければ多いほど効果が得られそうだ。ということが分かっていただけるかと思います。
インデックスの作成コマンド(DDL文)
インデックスを作成するには、以下のSQL(DDL: Data Definition Language)文を実行します。
CREATE INDEX [インデックス名] ON [テーブル名] ([列名])列は複数指定可能で、その場合は列名をカンマ区切りで指定します。
CREATE INDEX [インデックス名] ON [テーブル名] ([列名1],[列名2])CREATE INDEX文は様々なオプションが存在しますが、今は上記で良しとしましょう。
実際に作ってみる
実際にインデックスを作成してみます。
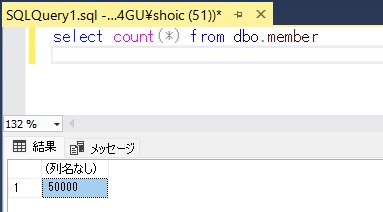
データベースにテーブルを用意し、データを投入しました。
テーブル名は「member」、データは50,000件投入しています。
※なお、私はテスト用データを作成する際に、以下のサイトを良く利用させて頂いています。手軽にテストデータが作成できて非常に助かっています。
・TM – WebTools
・UserLocal – 個人情報テストデータジェネレーター

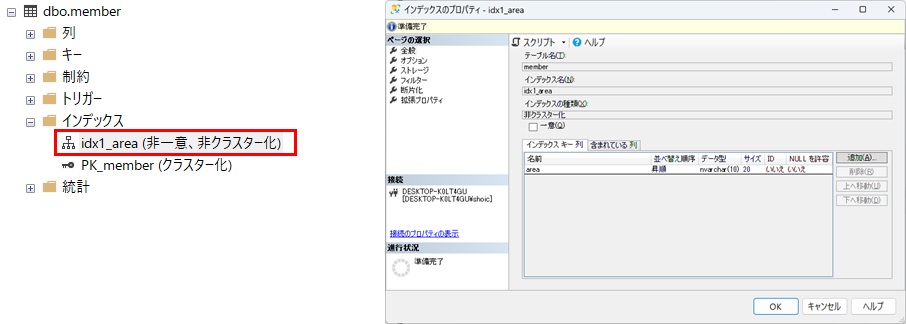
このmemberテーブルのカラム「area」に対してインデックスを作成します。
CREATE CLUSTERED INDEX idx1_area ON dbo.member (area)無事インデックスが作成されました。
インデックスを作成した効果ですが、50,000件の単一テーブル検索では体感が変わらないので、インデックス作成前後の実行プランで比較してみます。
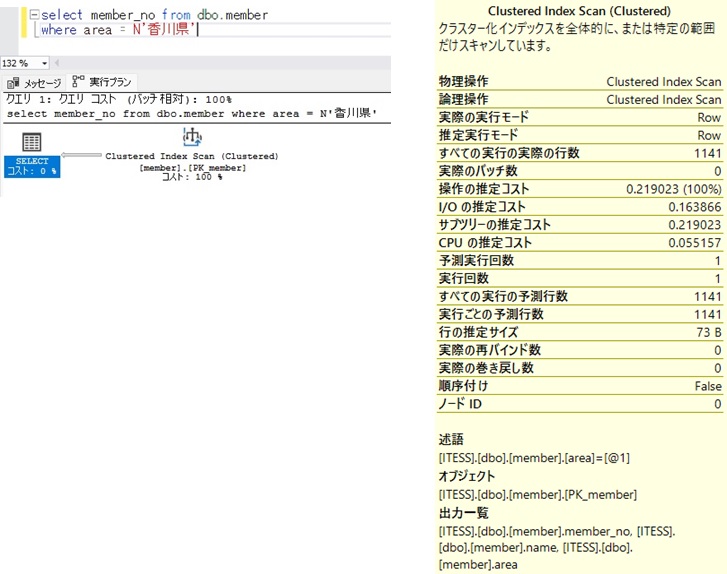
◆インデックス作成前
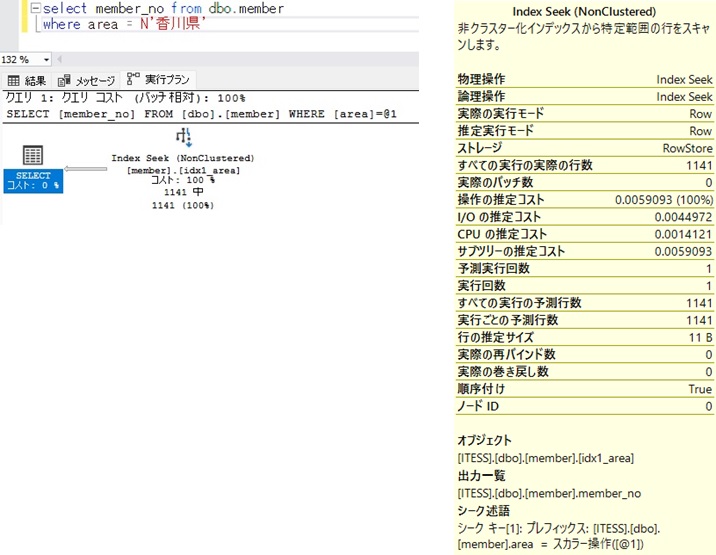
◆インデックス作成後
まとめると以下となります。
| 実行状態 | データベース上の操作内容 | 実行コスト |
|---|---|---|
| インデックス作成前 | Clustered Index Scan | 0.219023 |
| インデックス作成後 | Index Seak | 0.0059093 |
ここでは細かいことの説明は抜きにして、実行コスト(データベースが操作をするために使った労力と思ってください)を比較に留めますが、インデックス作成前後でデータベースの疲労度は約37%軽減されました!!
最後に
今回は、とりあえずインデックスを作成してみて、その効果に触れてみました。次回はもう少し突っ込んで、「じゃあどういう風にインデックスを作成すればいいのか?」について考えていきたいと思います。


コメント